Nginx在HTTP/2协议下使用limit_req限流出现响应延迟问题排查处理
最近在nginx中间层增加了限流配置,限流方式是通过limit_req模块限制server_name的请求速率,防止并发请求瞬间全部打到后端模块。Nginx配置完成后,只通过脚本在本地并发测试限流生效后就没关注了,但是最近突然发现通过CND代理的请求如果触发了限流策略,会导致在限速内通过的请求响应时间越来越长,记录一下该问题的分析处理过程。
一、Nginx限流配置说明
Nginx限流是通过limit_req模块实现的,该模块通过漏桶算法限制请求速率,配置方法如下:
1.在http块中定义zone
配置语法:limit_req_zone
rate速率说明:
| 速率参数写法 | 速率参数含义 |
|---|---|
| 10r/s | 每秒放行10个请求(该速率为平均速率,即每100毫秒放行1个请求) |
| 60r/m | 每分钟放行60个请求(该速率为平均速率,即每1秒放行1个请求) |
常用zone定义:
#按IP限流
limit_req_zone $binary_remote_addr zone=perip:10m rate=10r/s;
#按域名限流
limit_req_zone $server_name zone=perserver:10m rate=12r/s;
#按自定义key限流(如用户ID)
limit_req_zone $api_user zone=peruser:10m rate=5r/s; 注:使用自定义key限流的时候需要通过map指令动态生成限流键。
我们现在的限流是使用的按域名限流规则,规则如下:

2.在server块中应用限流规则
配置语法:limit_req zone=<名称> [burst=<数值>] [nodelay | delay=<数值>];
应用规则配置:
limit_req zone=perserver burst=12 nodelay;
limit_req_status 429; 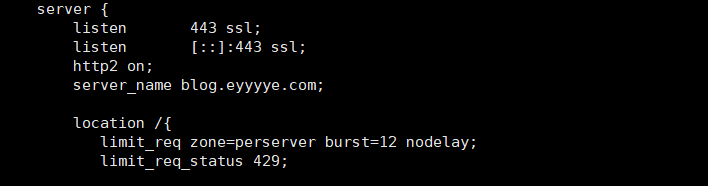
应用规则参数说明:
- burst:允许的最大突发请求,如果不设置该参数默认值为0,nginx会严格按照rate设置的速率放行;
- nodelay:burst内的突发请求立即放行,超出burst的请求立即拒绝,如果不设置该参数则突发请求排队,按rate速速率逐个处理;
- delay:burst内的突发请求前N个立即放行,第N+1个请求到burst上限之间的请求按照按rate速率逐个处理;
二、遇到的问题说明
1.问题描述
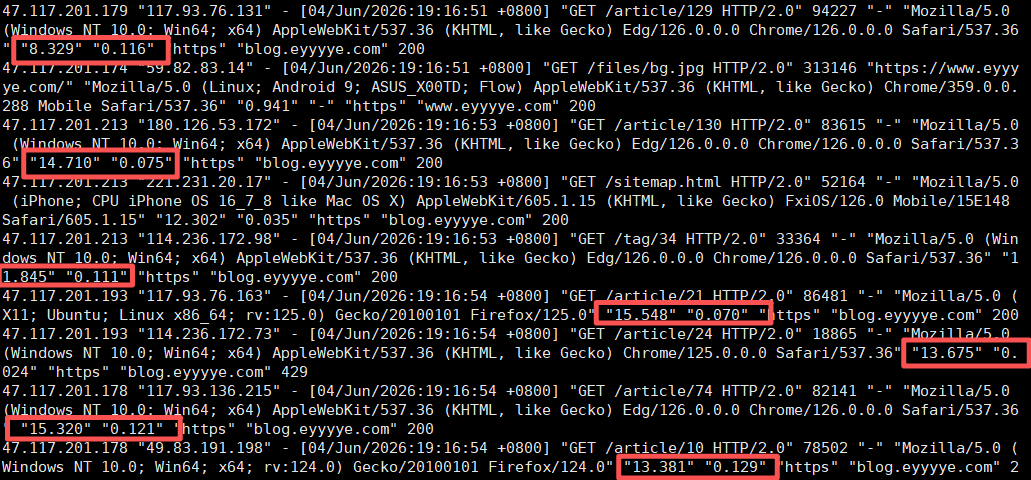
使用HTTP/1.1协议的时候,触发限流策略后,响应时间正常;在使用HTTP/2协议的时候,当触发限流策略后,nginx日志中显示总请求响应时间request_time在逐渐增加,但是后端响应时间upstream_response_time却还维持原来的零点几秒正常响应范围内,日志截图如下:
2.python测试脚本
import requests
import threading
import time
# 测试链接地址
URL = "https://blog.eyyyye.com/"
def send_batch_requests(count):
"""
发送指定数量的并发请求
:param count: 请求总数
"""
print(f"\n 正在发送 {count} 个请求到 {URL} ...")
results = []
lock = threading.Lock()
def worker(index):
try:
start_time = time.time()
r = requests.get(URL, timeout=5)
elapsed = time.time() - start_time
status = r.status_code
# 判断是否被限流
msg = "OK" if status == 200 else f"BLOCKED ({status})"
print(f" [请求 {index+1}] 状态码: {status} | 耗时: {elapsed:.3f}s | {msg}")
with lock:
results.append(status)
except Exception as e:
print(f" [请求 {index+1}] 错误: {e}")
with lock:
results.append(0)
threads = []
for i in range(count):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
# 统计结果
success = results.count(200)
blocked = len(results) - success
print(f"\n 统计结果: 成功 {success} 个, 被拦截/失败 {blocked} 个")
print("-" * 30)
if __name__ == "__main__":
while True:
try:
user_input = input("\n请输入要发送的请求数量 (输入 q 退出): ")
if user_input.lower() == 'q':
break
num = int(user_input)
if num > 0:
send_batch_requests(num)
else:
print("请输入一个正整数。")
except ValueError:
print("输入无效,请输入数字。")
except KeyboardInterrupt:
print("\n程序已退出。")
break
3.问题复现
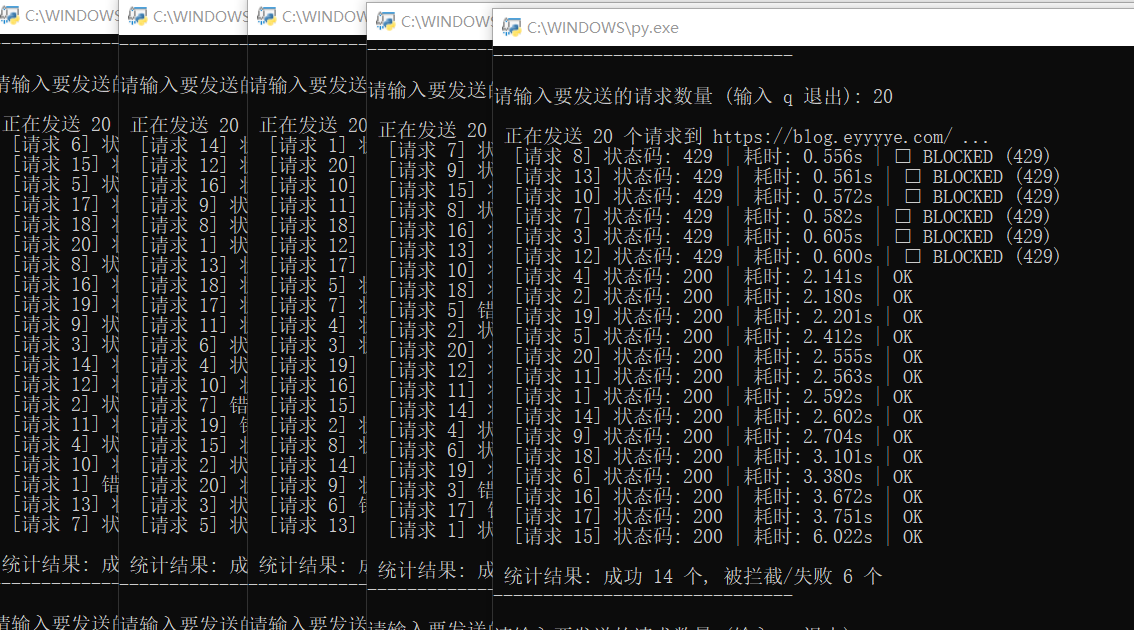
虽然python中的requests工具不支持HTTP/2协议,但是我们使用的阿里云ESA开启了HTTP2,所以我们只要在本地电脑使用测试脚本,直接向域名发起请求就可以测试复现。测试的时候在本地同时开启多个脚本,每个脚本控制少量并发,按顺序执行依次发起请求,就可以模拟持续触发限流的情况了,我们这里测试方法是本地开启5个测试脚本,每个脚本20个并发去测试。
测试脚本执行:
nginx日志:
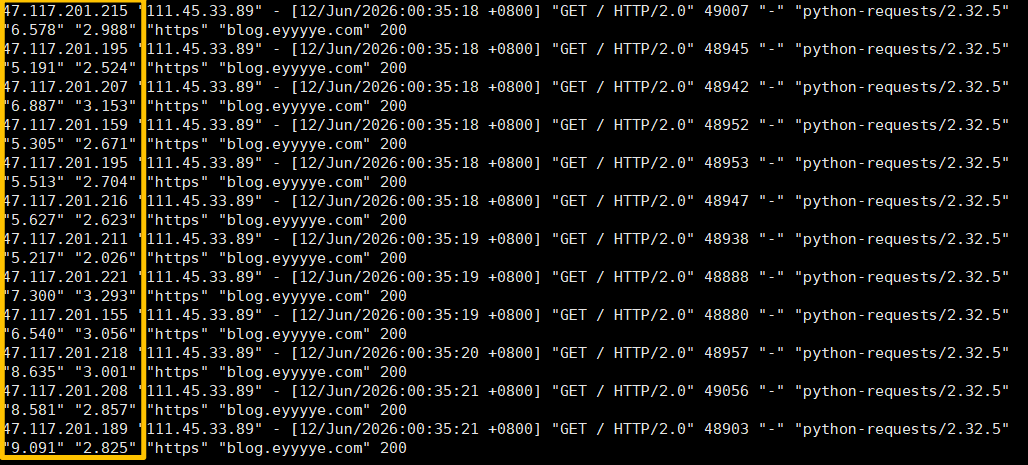
可以看到日志中的request_time时间一直在增长,问题已经复现成功。
三、问题排查过程
接下来我们就需要考虑这个问题发生的原因和怎么去处理了。
根据日志中upstream_response_time的响应时间一直是稳定状态,那么我们可以先排除后端的问题,同时因为HTTP/1.1的响应时间又是正常的,那么我们可以暂时推断问题原因可能出在HTTP/2和限流模块limit_req的配合上面。
再仔细看一下nginx日志,我们发现所有被限制的请求,request_time时间都是0:
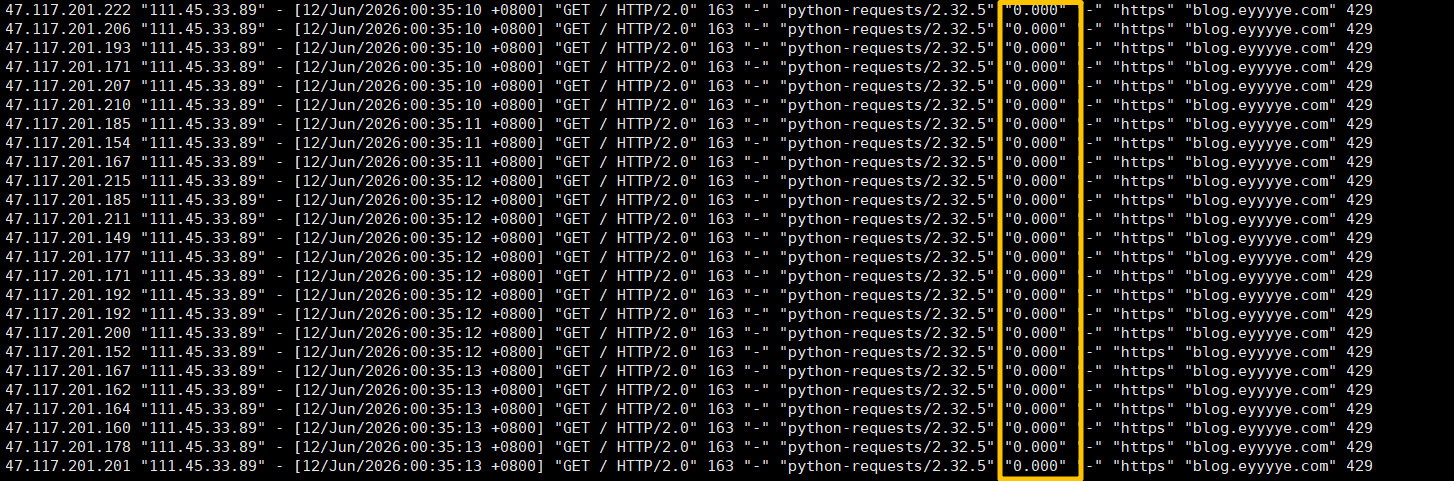
那么limit_req模块也没有什么问题了,剩下的可能就只有HTTP/2的问题了,我们先找AI问一下HTTP/2的特性:

通过分析HTTP/2的特点,我们发现可能影响响应时间有多路复用、流优先级和流量控制。先看多路复用,这个功能是在同一个TCP连接中可以并行处理多个请求或者响应,但是我们的并发的多个请求通过ESA透传到nginx的,每个请求都是一条TCP连接,所以不是这个功能影响的,同时流优先级也是在同一条TCP连接中,也不应该影响响应时间,那会是流量控制功能么,我们来让AI解释一下HTTP/2的流量控制原理:

看这个描述,HTTP/2的滑动窗口同样也是在单个TCP连接中生效,貌似也不是影响响应时间的原因呀,那么还有哪里漏掉了呢?有没有可能是ESA的问题呢?我们绕过ESA直接请求源站测试下:
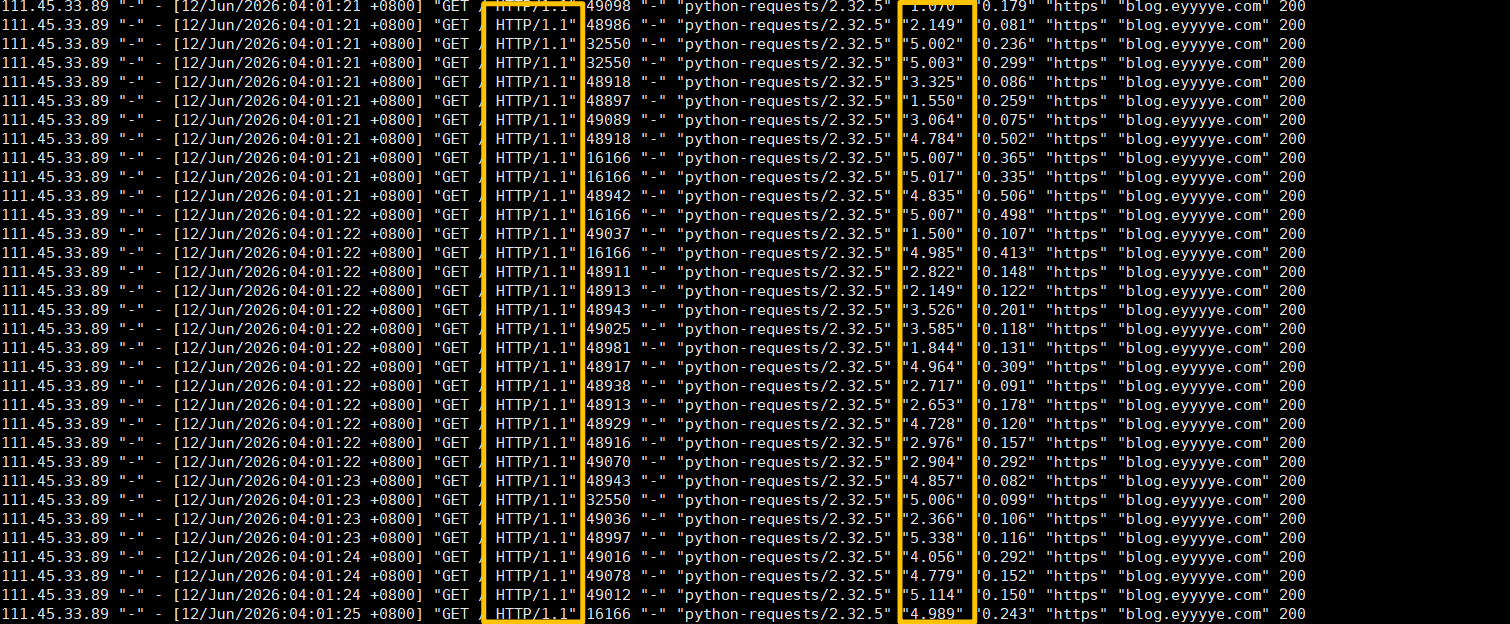
好像不太对,为什么HTTP/1.1也出现这个并发响应延迟的问题了呢,之前测试为什么没发现呢。回忆一下之前测试的流程,是在服务器上直接测试的,再去测试看看:
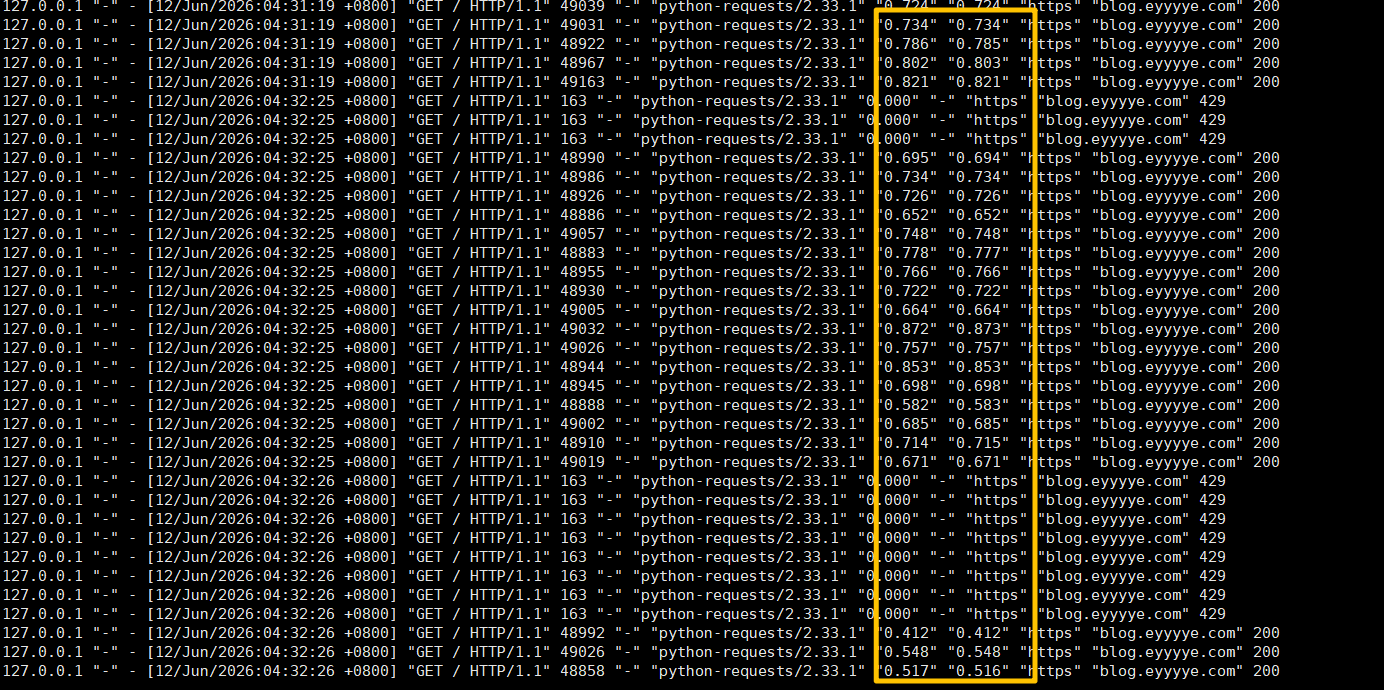
可以看到服务器上脚本测试结果request_time和upstream_response_time基本一样,而在本地用户电脑上请求的时候request_time响应时间逐渐增加upstream_response_time还保持在零点几秒内,那么问题原因可能就是网络部分了,我们看一下测试的时候网络状况:


可以看到服务器的出口带宽已经跑满了。那么我们折腾了半天排查的并发响应延迟的问题原因就确定了,是并发数量太多,而服务器出口带宽不够导致的网络拥塞排队。
四、问题处理
既然确定了原因,那就可以开始着手处理了。处理方法嘛,要么花钱升级带宽,要么调整nginx配置优化响应数据包大小。
现在我们每个响应大概50KB左右,所以我们可以开启gzip压缩来降低响应数据包大小:
gzip on;
gzip_types application/json;
gzip_min_length 1000;
gzip_comp_level 3; 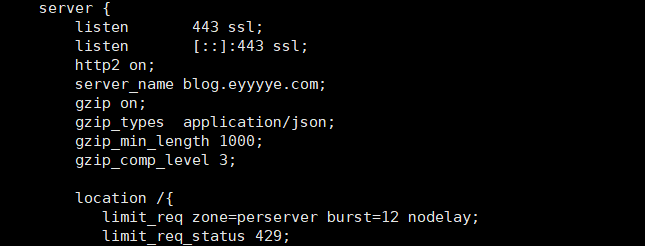
重启nginx生效后再测试看看:
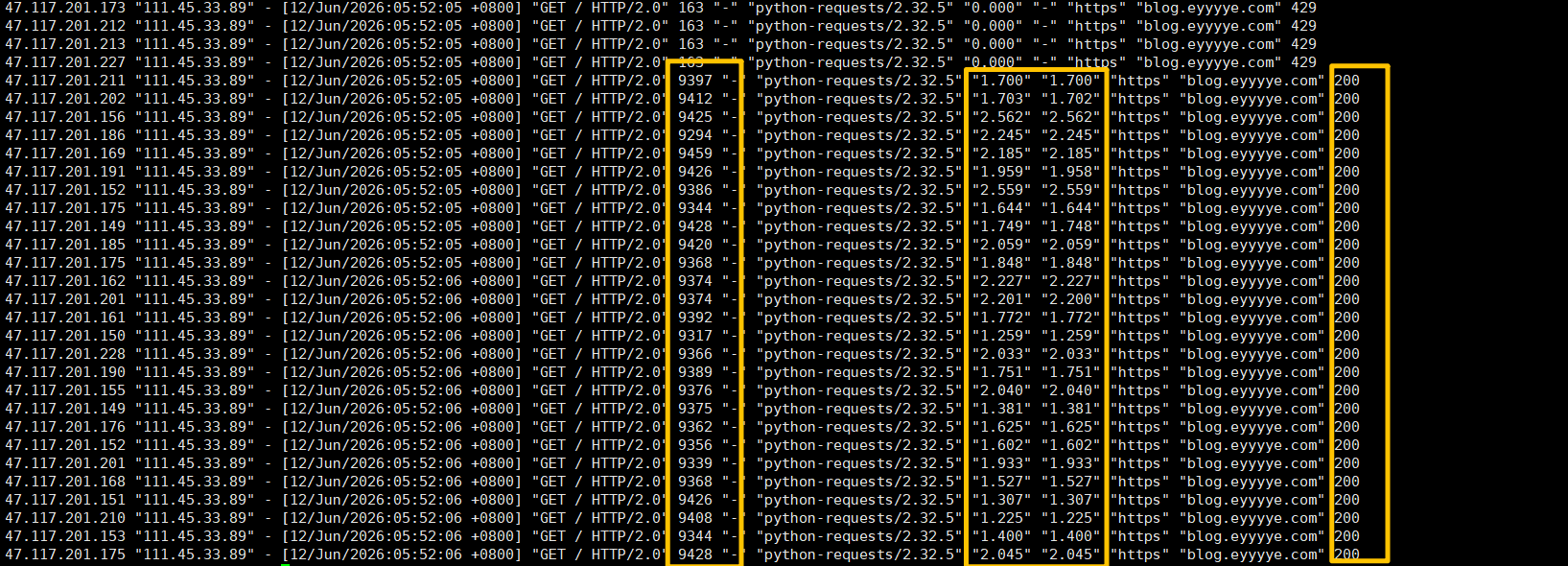
可以看到响应内容大小body_bytes_sent已经从50K压缩到9KB左右了,这样在限速内的请求就再也不会超过带宽啦。
扩展说明:
1.nginx开启gzip压缩会占用cpu资源,压缩等级越高占用cpu越多,一般为了平衡CPU,开到3级就够了。
2.参考文档1:https://nginx.org/en/docs/http/ngx_http_limit_req_module.html
- 本文标签: Nginx Linux Python
- 本文链接: https://blog.eyyyye.com/article/135
- 版权声明: 本文由爱做梦的比特原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐

相关文章
关于我





